

A/B testing splits site visitors 50/50 between a management and a variation. A/B break up testing is a new term for an old technique—controlled experimentation.
But for all of the content material on the market about it, folks nonetheless check the mistaken issues and run A/B tests incorrectly.
Right here’s what we’ll cowl on this tutorial:
What’s A/B testing?
A/B testing is a experimentation course of the place two or extra variants (A and B) are in contrast, in an effort to decide which variable is simpler.
When researchers check the efficacy of latest medication, they use a “break up check.” In actual fact, most analysis experiments could possibly be thought-about a “break up check,” full with a hypothesis, a management, a variation, and a statistically calculated end result.
That’s it. For instance, if you happen to ran a easy A/B check, it could be a 50/50 site visitors break up between the unique web page and a variation:
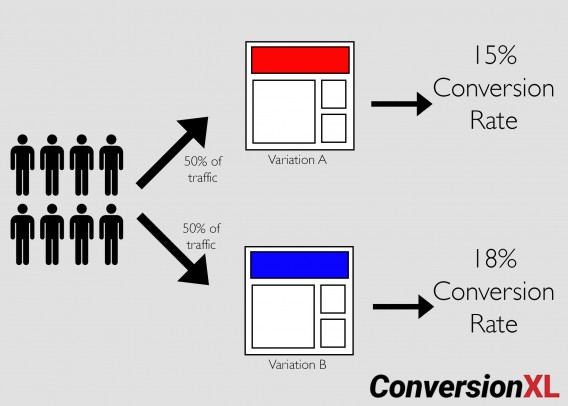
For conversion optimization, the primary distinction is the variability of Web site visitors. In a lab, it’s simpler to regulate for exterior variables. On-line, you may mitigate them, nevertheless it’s troublesome to create a purely managed check.
As well as, testing new medication requires an virtually sure diploma of accuracy. Lives are on the road. In technical phrases, your interval of “exploration” could be for much longer, as you wish to be rattling positive that you just don’t commit a Type I error (false positive).
On-line, the method for A/B split-testing considers enterprise objectives. It weighs danger vs. reward, exploration vs. exploitation, science vs. enterprise. Subsequently, we view outcomes via a special lens and make selections in a different way than these working assessments in
You possibly can, in fact, create greater than two variations. Exams with greater than two variations are often called A/B/n assessments. When you have sufficient site visitors, you may check as many variations as you want. Right here’s an instance of an A/B/C/D check, and the way a lot site visitors every variation is allotted:
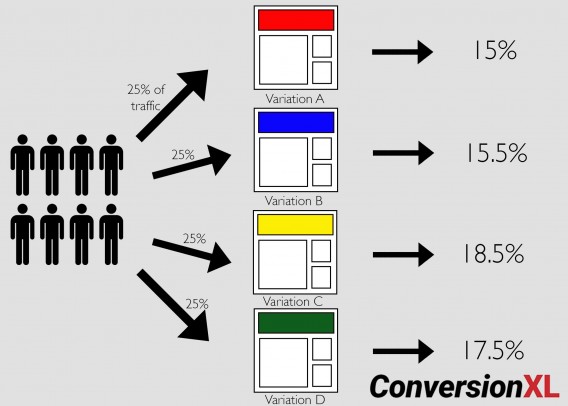
A/B/n assessments are nice for implementing extra variations of the identical speculation, however they require extra site visitors as a result of they break up it amongst extra pages.
A/B assessments, whereas the most popular, are only one sort of on-line experiment. You can too run multivariate and bandit tests.
A/B Testing, multivariate testing, and bandit algorithms: What’s the Distinction?
A/B/n assessments are managed experiments that run a number of variations in opposition to the unique web page. Outcomes evaluate conversion charges among the many variations primarily based on a single change.
Multivariate assessments check a number of variations of a web page to isolate which attributes trigger the biggest influence. In different phrases, multivariate assessments are like A/B/n assessments in that they check an unique in opposition to variations, however every variation comprises totally different design parts. For instance:
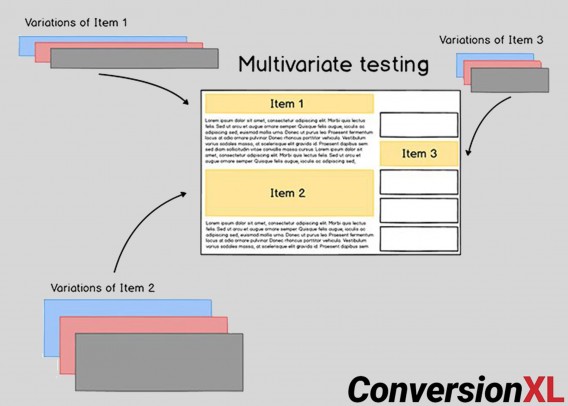
Every component has a particular influence and use case that can assist you get probably the most out of your web site. Right here’s how:
- Use A/B testing to find out one of the best layouts.
- Use multivariate assessments to shine layouts and guarantee all parts work together nicely collectively.
You’ll want to a ton of site visitors to the web page you’re testing earlier than even contemplating multivariate testing. However when you have sufficient site visitors, you must use each varieties of assessments in your optimization program.
Most businesses prioritize A/B testing since you’re normally testing extra vital modifications (with larger potential impacts
Bandit algorithms are A/B/n assessments that replace in actual time primarily based on the efficiency of every variation.
In essence, a bandit algorithm begins by sending site visitors to 2 (or extra) pages: the unique and the variation(s). Then, to “pull the successful slot machine arm extra typically,” the algorithm updates primarily based on which variation is “successful.” Finally, the algorithm absolutely exploits the best choice:
One good thing about bandit testing is that bandits mitigate “remorse,” which is the misplaced conversion alternative you expertise whereas testing a probably worse variation. This chart from Google explains that very nicely:
Bandits and A/B/n assessments every have a objective. Generally, bandits are nice for:
It doesn’t matter what sort of check you run, it’s necessary to have a course of that improves your probabilities of success. This implies working extra assessments, successful extra assessments, and making larger lifts.
enhance A/B check outcomes
Ignore weblog posts that inform you “99 Issues You Can A/B Take a look at Proper Now.” They’re a waste of time and site visitors. A course of will make you extra money.
Some 74% of optimizers with a structured strategy to conversion additionally declare improved gross sales. These with out a structured strategy keep in what Craig Sullivan calls the “Trough of Disillusionment.” (Except their outcomes are plagued by false positives, which we’ll get into later.)
To simplify a successful course of, the construction goes one thing like this:
- Analysis;
- Prioritization;
- Experimentation;
- Analyze, be taught, repeat.
Analysis: Getting data-driven insights
To start optimization, you should know what your customers are doing and why.
Earlier than you concentrate on optimization and testing, nonetheless, solidify your high-level technique and transfer down from there. So, suppose on this order:
- Outline your enterprise goals.
- Outline your web site objectives.
- Outline your Key Performance Indicators.
- Outline your goal metrics.

As soon as you recognize the place you wish to go, you can acquire the information essential to get there. To do that, we advocate the ResearchXL Framework.
Right here’s the manager abstract of the method we use at CXL:
- Heuristic analysis;
- Technical evaluation;
- Web analytics analysis;
- Mouse-tracking analysis;
- Qualitative surveys;
- User testing and copy testing.
Heuristic evaluation is about as shut as we get to “greatest practices.” Even after years of expertise, you continue to can’t inform precisely what’s going to work. However you may establish alternative areas. As Craig Sullivan puts it:

Craig Sullivan:
“My expertise in observing and fixing issues: These patterns do make me a greater diagnostician, however they don’t perform as truths—they information and inform my work, however they don’t present ensures.”
Humility is essential. It additionally helps to have a framework. When doing heuristic evaluation, we assess every web page primarily based on the next:
- Relevancy;
- Readability;
- Worth;
- Friction;
- Distraction.
Technical evaluation is an often-overlooked space. Bugs—in the event that they’re round—are a conversion killer. You might suppose your web site works completely when it comes to person expertise and performance. However does it work equally nicely with each browser and gadget? Most likely not.
This can be a low-hanging—and extremely worthwhile—fruit. So, begin by:
Net analytics evaluation is subsequent. Very first thing’s first: Be certain all the things is working. (You’d be shocked by what number of analytics setups are damaged.)
Google Analytics (and different analytics setups) are a course in themselves, so I’ll go away you with some useful hyperlinks:
Subsequent is mouse-tracking evaluation, which incorporates heat maps, scroll maps, click maps, form analytics, and user session replays. Don’t get carried away with fairly visualizations of click on maps. Be sure to’re informing your bigger objectives with this step.
Qualitative analysis tells you the why that quantitative evaluation misses. Many individuals suppose that qualitative evaluation is “softer” or simpler than quantitative, nevertheless it ought to be simply as rigorous and might present insights as necessary as these from analytics.
For qualitative research, use issues like:
With copy testing, you find out how your precise audience perceives the copy, what clear or unclear, what arguments they care about or not.
After thorough conversion analysis, you’ll have a lot of knowledge. The following step is to prioritize that knowledge for testing.
prioritize A/B check hypotheses
There are various frameworks to prioritize your A/B assessments, and you would even innovate with your individual system. Right here’s a technique to prioritize work shared by Craig Sullivan.
When you undergo all six steps, you will discover points—some extreme, some minor. Allocate each
- Take a look at. This bucket is the place you place stuff for testing.
- Instrument. This could contain fixing, including, or enhancing tag/occasion dealing with in analytics.
- Hypothesize. That is the place you’ve discovered a web page, widget, or course of that’s not working nicely however doesn’t reveal a transparent resolution.
- Simply Do It. Right here’s the bucket for no-brainers. Simply do it.
- Examine. If an merchandise is on this bucket, you should ask questions or dig deeper.
Rank every subject from 1 to five stars (1 = minor, 5 = essential). There are two standards which are extra necessary than others when giving a rating:
- Ease of implementation (time/complexity/danger). Generally, knowledge tells you to construct a characteristic that can take months to develop. Don’t begin there.
- Alternative. Rating points subjectively primarily based on how massive a raise or change they might generate.
Create a spreadsheet with your entire knowledge. You’ll have a prioritized testing roadmap.
We created our own prioritization model to weed out subjectivity (as attainable). It’s predicated on the necessity to convey knowledge to the desk. It’s referred to as PXL and appears like this:
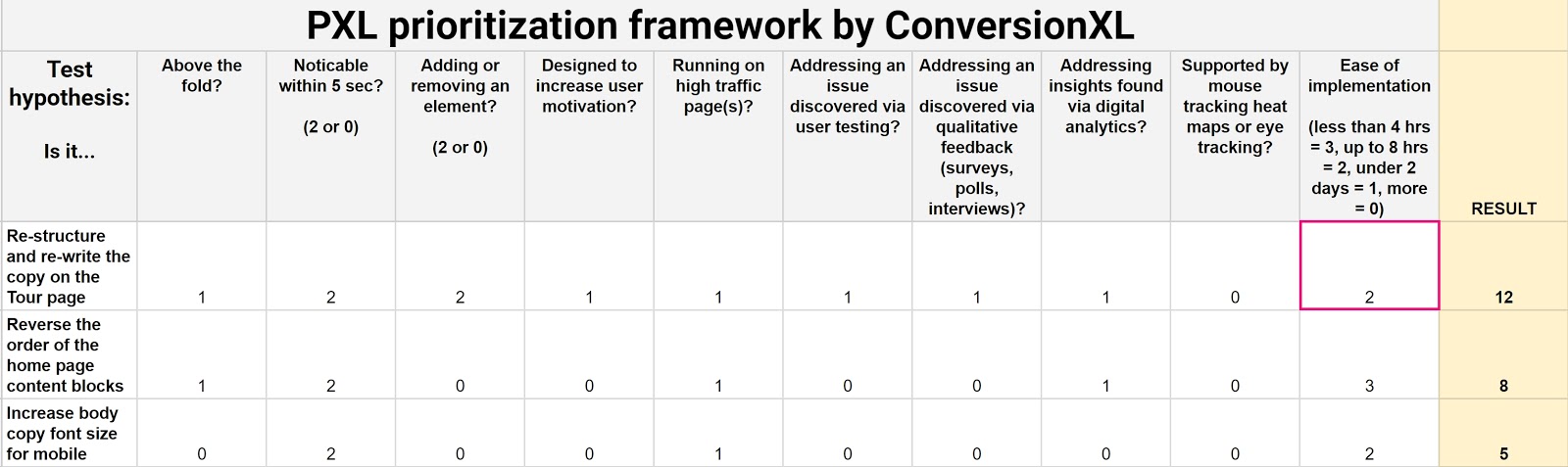
Grab your own copy of this spreadsheet template here. Simply click on File > Make a Copy to make it your individual.
As a substitute of guessing what the influence may be, this framework asks you a set of questions on it:
- Is the change above the fold? Extra folks discover above-the-fold modifications. Thus, these modifications usually tend to have an effect.
- Is the change noticeable in below 5 seconds? Present a bunch of individuals the management after which the variation(s). Can they inform a distinction after 5 seconds? If not, it’s more likely to have much less of an influence.
- Does it add or take away something? Larger modifications like eradicating distractions or including key data are likely to have extra of an influence.
- Does the check run on high-traffic pages? An enchancment to a heavy-traffic web page generates larger returns.
Many potential check variables require knowledge to prioritize your hypotheses. Weekly discussions that ask these 4 questions will make it easier to prioritize testing primarily based on knowledge, not opinions:
- Is it addressing a difficulty found by way of person testing?
- Is it addressing a difficulty found by way of qualitative suggestions (surveys, polls, interviews)?
- Is the speculation supported by mouse monitoring, warmth maps, or eye tracking?
- Is it addressing insights discovered by way of digital analytics?
We additionally put bounds on Ease of implementation by bracketing solutions in accordance with the estimated time. Ideally, a check developer is a part of prioritization discussions.
Grading PXL
We assume a binary scale: You need to select one or the opposite. So, for many variables (except in any other case famous), you select both a 0 or a 1.
However we additionally wish to weight variables primarily based on significance—how noticeable the change is, if one thing is added/eliminated, ease of implementation. For t
Customizability
We constructed this mannequin with the assumption you can and may customise variables primarily based on what issues to your enterprise.
For instance, possibly you’re working with a branding or person expertise staff, and hypotheses should conform to model tips. Add it as a variable.
Possibly you’re at a startup whose acquisition engine is fueled by web optimization. Possibly your funding will depend on that stream of shoppers. Add a class like, “doesn’t intervene with web optimization,” which could alter some headline or copy tests.
All organizations function below totally different assumptions. Customizing the template can account for them and optimize your optimization program.
Whichever framework you employ, make it systematic and comprehensible to anybody on the staff, in addition to stakeholders.
How lengthy to run A/B assessments
First rule: Don’t cease a check simply because it reaches statistical significance. That is in all probability the most typical error dedicated by newbie optimizers with good intentions.
In case you name assessments while you hit significance, you’ll discover that almost all lifts don’t translate to elevated income (that’s the purpose, in spite of everything). The “lifts” were, in fact, imaginary.
Take into account this: When 1,000 A/A tests (two equivalent pages) had been run:
- 771 experiments out of 1,000 reached 90% significance in some unspecified time in the future.
- 531 experiments out of 1,000 reached 95% significance in some unspecified time in the future.
Stopping assessments at significance dangers false positives and excludes external validity threats, like seasonality.
Predetermine a pattern dimension and run the check for full weeks, normally no less than two enterprise cycles.
How do you predetermine pattern dimension? There are many great tools. Right here’s the way you’d calculate your pattern dimension with Evan Miller’s software:
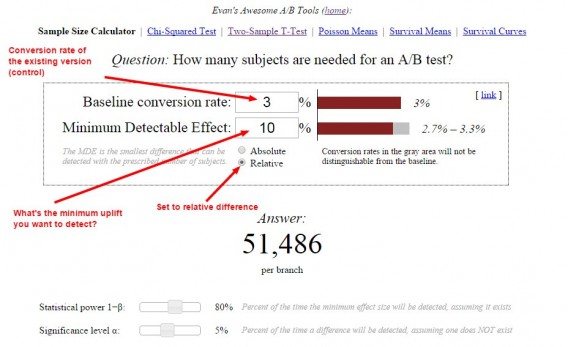
On this instance, we informed the software that we’ve a 3% conversion fee and wish to detect no less than 10% uplift. The software tells us that we want 51,486 guests per variation earlier than we will take a look at statistical significance ranges.
Along with
For sensible functions, know that 80% energy is the usual for A/B testing tools. To achieve such a degree, you want both a big pattern dimension, a big impact dimension, or an extended length check.
There are not any magic numbers
A variety of weblog posts

Andrew Anderson:
“It’s by no means about what number of conversions. It’s about having sufficient knowledge to validate primarily based on consultant samples and consultant conduct.
100 conversions is feasible in solely probably the most distant circumstances and with an extremely excessive delta in conduct, however provided that different necessities like conduct over time, consistency, and regular distribution happen. Even then, it’s has a extremely excessive likelihood of a Kind I error, false optimistic.”
We would like a consultant pattern. How can we get that? Take a look at for 2 enterprise cycles to mitigate exterior components:
- Day of the week. Your every day site visitors can differ so much.
- Visitors sources. Except you wish to personalize the expertise for a devoted supply.
- Weblog put up and publication publishing schedule.
- Return guests. Individuals might go to your web site, take into consideration a purchase order, then come again 10 days later to purchase it.
- Exterior occasions. A mid-month payday might have an effect on buying, for instance.
Watch out with small pattern sizes. The Web is stuffed with case studies steeped in shitty math. Most research (in the event that they ever launched full numbers) would reveal that publishers judged check variations on 100 guests or a raise from 12 to 22 conversions.
When you’ve arrange all the things appropriately, keep away from peeking (or letting your boss peek) at check outcomes earlier than the check finishes. This may end up in calling a end result early as a result of “recognizing a pattern” (not possible). What you’ll discover is that many check outcomes regress to the imply.
Regression to the imply
Typically, you’ll see outcomes differ wildly within the first few days of the check. Positive sufficient, they have an inclination to converge because the check continues for the following few weeks. Right here’s an instance from an ecommerce web site:
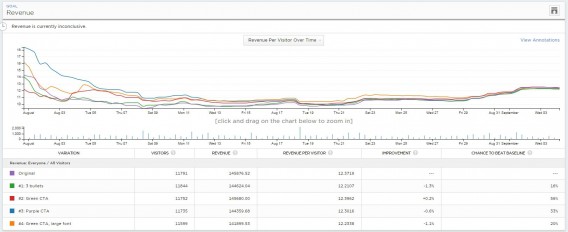
First couple of days: Blue (variation #3) is successful massive—like $16 per customer vs. $12.50 for Management. Numerous folks would (mistakenly) finish the check right here.- After 7 days: Blue nonetheless successful, and the relative distinction is massive.
- After 14 days: Orange (#4) is successful!
- After 21 days: Orange nonetheless successful!
- Finish: No distinction.
In case you’d referred to as the check at lower than 4 weeks, you’d have made an faulty conclusion.
There’s a associated subject: the novelty impact. The novelty of your modifications (e.g., larger blue button) brings more attention to the variation. With time, the raise disappears as a result of the change is now not novel.
It’s one among many complexities associated to A/B testing. We now have a bunch of weblog posts dedicated to such matters:
Are you able to run a number of A/B assessments concurrently?
You wish to velocity up your testing program and run extra assessments—high-tempo testing. However are you able to run a couple of A/B check on the similar time
Some consultants say you shouldn’t do a number of assessments concurrently. Some say it’s nice. Normally, you can be nice working a number of simultaneous assessments; excessive interactions are unlikely.
Except you’re testing actually necessary stuff (e.g., one thing that impacts your enterprise mannequin, way forward for the corporate), the advantages of testing quantity will possible outweigh the noise in your knowledge and occasional false positives.
If there’s a excessive danger of interplay between a number of assessments, scale back the variety of simultaneous assessments and/or let the assessments run longer for improved accuracy.
If you wish to be taught extra, learn these posts:
arrange A/B assessments
When you’ve received a prioritized listing of check concepts, it’s time to kind a speculation and run an experiment. A speculation defines why you consider an issue happens. Moreover, an excellent speculation:
- Is testable. It’s measurable, so it may be examined.
- Solves a conversion downside. Cut up-testing solves conversion issues.
- Gives market insights. With a well-articulated speculation, your split-testing outcomes offer you details about your prospects, whether or not the check “wins” or “loses.”
Craig Sullivan has a hypothesis kit to simplify the method:
- As a result of we noticed (knowledge/suggestions),
- We count on that (change) will trigger (influence).
- We’ll measure this utilizing (knowledge metric).
And the superior one:
- As a result of we noticed (qualitative and quantitative knowledge),
- We count on that (change) for (inhabitants) will trigger (influence[s]).
- We count on to see (knowledge metric[s] change) over a interval of (X enterprise cycles).
Technical stuff
Right here’s the enjoyable half: You possibly can lastly take into consideration picking a tool.
Whereas that is the very first thing many individuals take into consideration, it’s not an important. Technique and statistical data come first.
That mentioned, there are just a few variations to remember. One main categorization in instruments is whether or not they’re server-side or client-side testing tools.
Server-side instruments render code on the server degree. They ship a randomized model of the web page to the viewer with no modification on the customer’s browser. Shopper-side instruments ship the identical web page, however JavaScript on the shopper’s browser manipulates the looks on the unique and the variation.
Shopper-side testing instruments embody Optimizely, VWO, and Adobe Goal. Conductrics has capabilities for each, and SiteSpect does a proxy server-side technique.
What does all this imply for you? In case you’d like to avoid wasting time up entrance, or in case your staff is small or lacks growth sources, client-side instruments can get you up and working quicker. Server-side requires growth sources however can typically be extra sturdy.
Whereas organising assessments is barely totally different relying on which software you employ, it’s typically so simple as signing up in your favourite software and following their directions, like placing a JavaScript snippet in your web site.
Past that, you should arrange Objectives (to know when a conversion has been made). Your testing software will observe when every variation converts guests into prospects.
Expertise that come in useful when organising A/B assessments are HTML, CSS, and JavaScript/JQuery, in addition to design and copywriting skills to craft variations. Some instruments enable use of a visible editor, however that limits your flexibility and control.
analyze A/B check outcomes
Alright. You’ve carried out your analysis, arrange your check appropriately, and the check is lastly cooked. Now, on to evaluation. It’s not so simple as a glimpse on the graph out of your testing software.
One factor you must at all times do: Analyze your test results in Google Analytics. It doesn’t simply improve your evaluation capabilities; it additionally means that you can be extra assured in your knowledge and resolution making.
Your testing software could possibly be recording knowledge incorrectly. When you have no different supply in your check knowledge, you may by no means make certain whether or not to belief it. Create a number of sources of information.
What occurs if there’s no distinction between variations? Don’t transfer on too rapidly. First, understand two issues:
1. Your speculation might need been proper, however implementation was mistaken.
Let’s say your qualitative analysis says that concern about safety is a matter. What number of methods are you able to beef up the perception of security? Limitless.
The secret is iterative testing, so if you happen to had been on to one thing, attempt just a few iterations.
2. Even when there was no distinction total, the variation would possibly beat the management in a phase or two.
In case you received a raise for returning guests and cell guests—however a drop for brand spanking new guests and desktop customers—these segments would possibly cancel one another out, making it seem to be there’s “no distinction.” Analyze your test across key segments to analyze that risk.
Information segmentation for A/B assessments
The important thing to studying in A/B testing is segmenting. Though B would possibly lose to A within the total outcomes, B would possibly beat A in sure segments (natural, Fb, cell, and so forth).
There are a ton of segments you may analyze. Optimizely lists the next potentialities:
- Browser sort;
- Supply sort;
- Cell vs. desktop, or by gadget;
- Logged-in vs. logged-out guests;
- PPC/SEM marketing campaign;
- Geographical areas (metropolis, state/province, nation);
- New vs. returning guests;
- New vs. repeat purchasers;
- Energy customers vs. informal guests;
- Males vs. ladies;
- Age vary;
- New vs. already-submitted leads;
- Plan varieties or loyalty program ranges;
- Present, potential, and former subscribers;
- Roles (in case your web site has, as an illustration, each a purchaser and vendor function).
On the very least—assuming you might have an satisfactory pattern dimension—take a look at these segments:
- Desktop vs. pill/cell;
- New vs. returning;
- Visitors that lands on the web page vs. site visitors from inner hyperlinks.
Just be sure you have sufficient pattern dimension throughout the phase. Calculate it prematurely, and be cautious if it’s lower than 250–350 conversions per variation inside in a given phase.
In case your therapy carried out nicely for a particular phase, it’s time to contemplate a personalized approach for these customers.
archive previous A/B assessments
A/B testing isn’t nearly lifts, wins, losses, and testing random shit. As Matt Gershoff mentioned, optimization is about “gathering data to tell selections,” and the learnings from statistically legitimate A/B assessments contribute to the better objectives of development and optimization.
Good organizations archive their test results and plan their strategy to testing systematically. A structured strategy to optimization yields better development and is less-often restricted by local maxima.
So right here’s the robust half: There’s no single greatest technique to construction your data administration. Some corporations use refined, internally constructed instruments; some use third-party instruments; and a few use Excel and Trello.
If it helps, listed below are three instruments constructed particularly for conversion optimization venture administration:
It’s necessary to speak throughout departments and to executives. Typically, A/B check outcomes aren’t intuitive to a layperson. Visualization helps.
Annemarie Klaassen and Ton Wesseling wrote an awesome post on visualizing A/B test results. Right here’s what they got here up with:
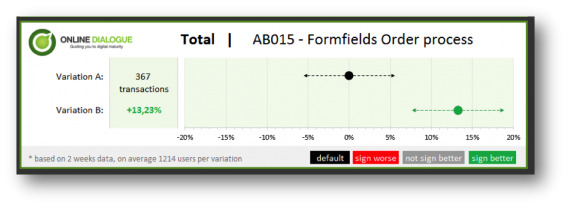
A/B testing statistics
Statistical data is useful when analyzing A/B check outcomes. We went over a few of it within the part above, however there’s extra to cowl.
Why do you should know statistics? Matt Gershoff likes to cite his faculty math professor: “How will you make cheese if you happen to don’t know the place milk comes from?!”
There are three phrases you must know earlier than we dive into the nitty gritty of A/B testing statistics:
- Imply. We’re not measuring all conversion charges, only a pattern. The typical is consultant of the entire.
- Variance. What’s the pure variability of a inhabitants? That impacts our outcomes and the way we use them.
- Sampling. We are able to’t measure the true conversion fee, so we choose a pattern that’s (hopefully) consultant.
What’s a p-value?
Many use the time period “statistical significance” inaccurately. Statistical significance by itself shouldn’t be a stopping rule, so what’s it and why is it necessary?
To begin with, let’s go over p-values, that are additionally very misunderstood. As FiveThirtyEight just lately identified, even scientists can’t easily explain p-values.
A p-value is the measure of proof in opposition to the null speculation (the management, in A/B testing parlance). A p-value doesn’t inform us the likelihood that B is healthier than A.
Equally, it doesn’t inform us the likelihood that we’ll make a mistake in deciding on B over A. These are widespread misconceptions.
The p-value is the likelihood of seeing the present end result or a extra excessive one on condition that the null speculation is true. Or, “How stunning is that this end result?”
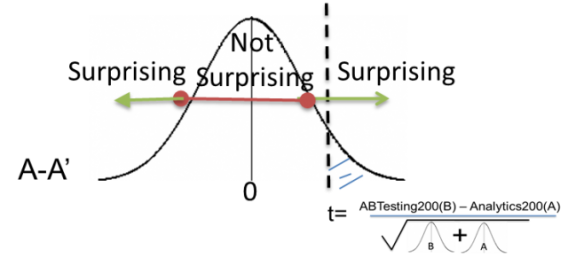
To sum it up, statistical significance (or a statistically vital end result) is attained when a p-value is lower than the importance degree (which is normally set at 0.05).
Significance in regard to statistical hypothesis testing can be the place the entire “one-tail vs. two-tail” subject comes up.
One-tail vs. two-tail A/B assessments
One-tailed tests enable for an impact in a single path. Two-tailed assessments search for an impact in two instructions—optimistic or adverse.
No must get very labored up about this. Gershoff from Conductrics summed it up nicely:

Matt Gershoff:
“In case your testing software program solely does one sort or the opposite, don’t sweat it. It’s tremendous easy to transform one sort to the opposite (however you should do that BEFORE you run the check) since the entire math is strictly the identical in each assessments. All that’s totally different is the importance threshold degree. In case your software program makes use of a one-tail check, simply divide the p-value related to the boldness degree you need to run the check by two. So, in order for you your two-tail check to be on the 95% confidence degree, then you definately would truly enter a confidence degree of 97.5%, or if at a 99%, then you should enter 99.5%. You possibly can then simply learn the check as if it was two-tailed.”
Confidence intervals and margin of error
Your conversion fee doesn’t merely say X%. It says one thing like X% (+/- Y). That second quantity is the boldness interval, and it’s of utmost significance to understanding your check outcomes.
In A/B testing, we use confidence intervals to mitigate the chance of sampling errors. In that sense, we’re managing the chance related to implementing a brand new variation.
So in case your software says one thing like, “We’re 95% assured that the conversion fee is X% +/- Y%,” then you should account for the +/- Y% because the margin of error.
How assured you might be in your outcomes relies upon largely on how massive the margin of error is. If the 2 conversion ranges overlap, you should maintain testing to get a legitimate end result.
Matt Gershoff gave an incredible illustration of how margin of error works:
Matt Gershoff:
“Say your buddy is coming to go to you from Spherical Rock and is taking TX-1 at 5 p.m. She desires to understand how lengthy it ought to take her. You say I’ve a 95% confidence that it’s going to take you about 60 minutes plus or minus 20 minutes. So your margin of error is 20 minutes, or 33%.
If she is coming at 11 a.m. you would possibly say, “It should take you 40 min, plus or minus 10 min,” so the margin of error is 10 minutes, or 25%. So whereas each are on the 95% confidence degree, the margin of error is totally different.”
Exterior validity threats
There’s a problem with working A/B assessments: Information isn’t stationary.
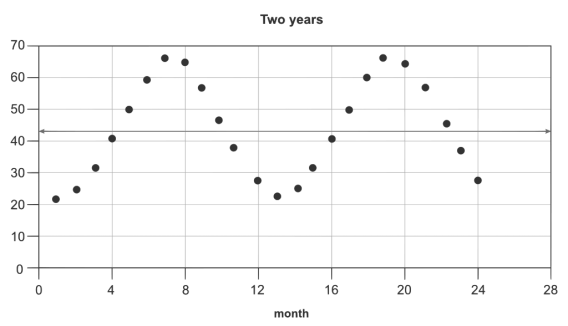
A stationary time sequence is one whose statistical properties (imply, variance, autocorrelation, and so forth.) are fixed over time. For a lot of causes, web site knowledge is non-stationary, which implies we will’t make the identical assumptions as with stationary knowledge. Listed below are just a few causes that knowledge would possibly fluctuate:
- Season;
- Day of the week;
- Holidays;
- Optimistic or adverse press mentions;
- Different advertising campaigns;
- PPC/SEM;
- web optimization;
- Phrase-of-mouth.
Others embody sample pollution, the glint impact, income monitoring errors, choice bias, and extra. (Read here.) These are issues to bear in mind when planning and analyzing your A/B assessments.
Bayesian or frequentist Stats
Bayesian or Frequentist A/B testing is one other scorching matter. Many common instruments have rebuilt their stats engines to characteristic a Bayesian methodology.
Right here’s the distinction (very a lot simplified): Within the Bayesian view, a likelihood is assigned to a speculation. Within the Frequentist view, a speculation is examined with out being assigned a likelihood.
Rob Balon, who carries a PhD in statistics and market analysis, says the talk is generally esoteric tail wagging from the ivory tower. “In reality,” he says, “most analysts out of the ivory tower don’t care that a lot, if in any respect, about Bayesian vs. Frequentist.”
Don’t get me mistaken, there are sensible enterprise implications to every methodology. However if you happen to’re new to A/B testing, there are far more necessary issues to fret about.
Now, how do you begin working A/B assessments?
Littered all through this information are tons of hyperlinks to exterior sources: articles, instruments, books and books. We’ve tried to compile all probably the most useful data in our A/B Testing course.
On prime of that, listed below are among the greatest sources (divided by classes).
A/B testing instruments
There are a whole lot of instruments for on-line experimentation. Right here’s an inventory of 53 conversion optimization tools, all reviewed by consultants. A few of the hottest A/B testing instruments embody:
A/B testing calculators
A/B testing statistics sources
A/B testing/CRO technique sources
Conclusion
A/B testing is a useful useful resource to anybody making selections in an internet setting. With somewhat bit of information and a whole lot of diligence, you may mitigate lots of the dangers that almost all starting optimizers face.
In case you actually dig into the data right here, you’ll be forward of 90% of individuals working assessments. In case you consider within the energy of A/B testing for continued income development, that’s a incredible place to be.
Information is a limiting issue that solely expertise and iterative studying can transcend. So get testing!
Engaged on one thing associated to this? Submit a remark within the CXL community!







{kind=link}